
Elon Musk氏がXで投稿した内容をもとに、Grokの次期基盤モデルらしき「V9-Medium」が話題になっています。投稿では、1.5T規模のモデル、Cursorデータの追加、そして2〜3週間後の公開見込みが語られています。
ただ、僕はここを少し冷静に見たいです。派手な数字より大事なのは、Grokが本当にコーディング実務で使いやすくなるのかです。そこが変わるなら、この話はかなり大きいです。
何が投稿されたのか
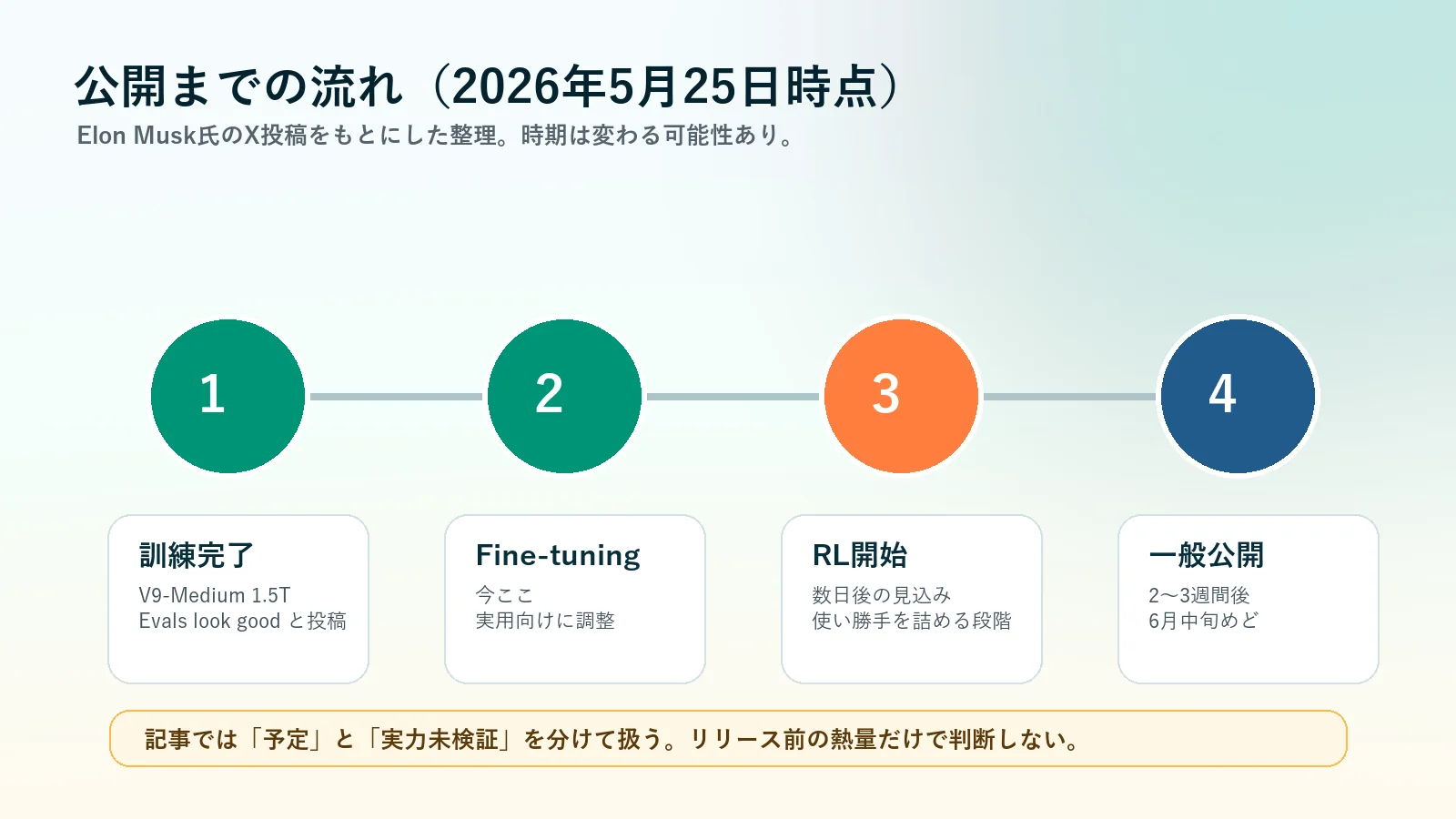
今回の話は、Musk氏のX投稿が出発点です。内容を要約すると、Grok foundation model V9-Mediumの訓練が完了し、評価は良好。補足訓練でCursorデータを多く追加し、今後も追加予定。現在はfine-tuning中で、数日後にreinforcement learningへ進み、公開までは2〜3週間、という流れです。
ここで大事なのは、まだ一般公開されたモデルではないことです。つまり、現時点で分かっているのは投稿ベースの工程説明であって、ベンチマークの詳細や実際の使い勝手はまだ見えていません。
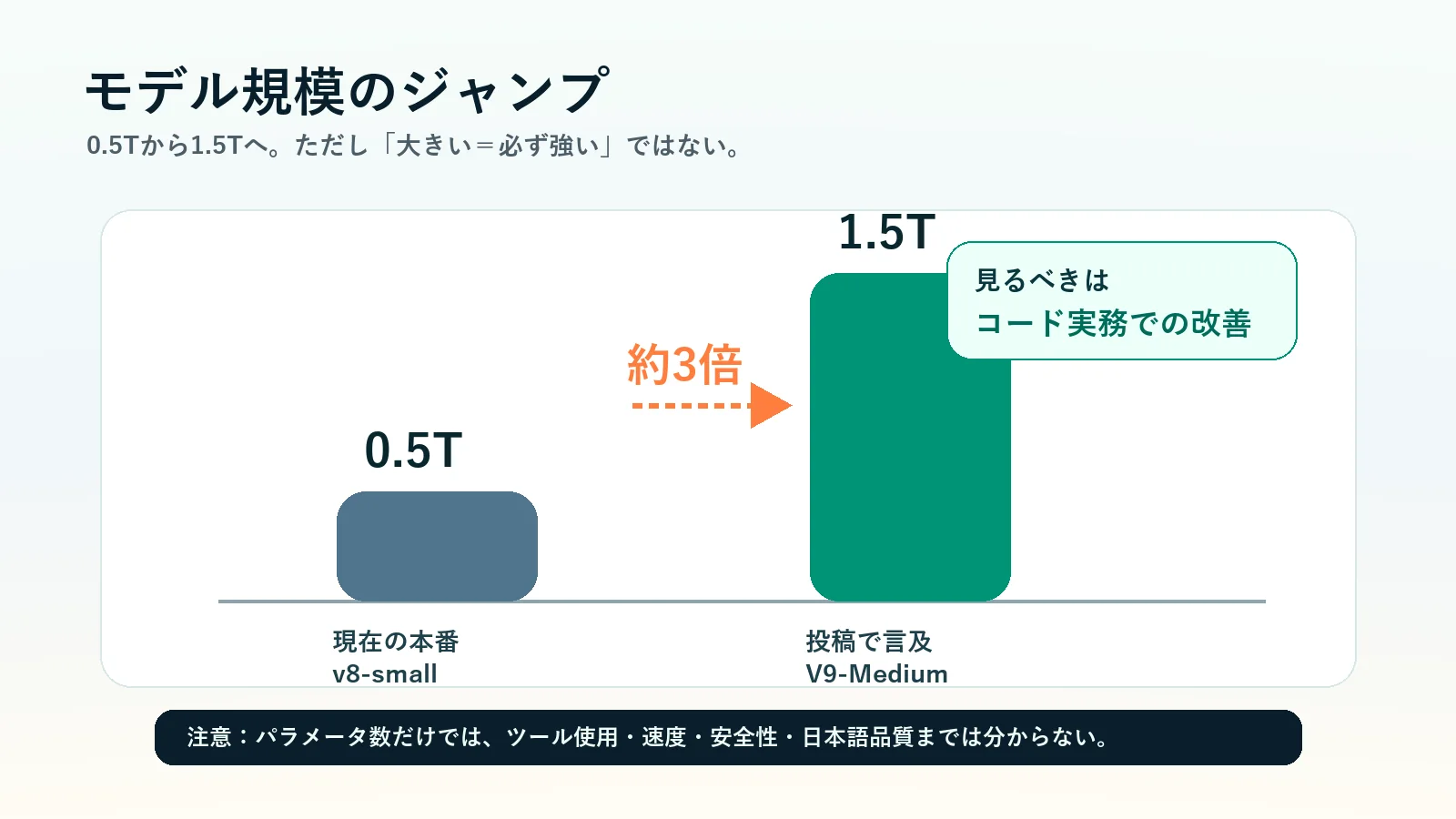
それでも注目される理由は分かります。現行のGrok本番トラフィックを支える0.5Tのv8-smallから、1.5TのV9-Mediumへ移るなら、規模だけで見れば約3倍です。しかも焦点が難しいコーディングタスクに向いている。
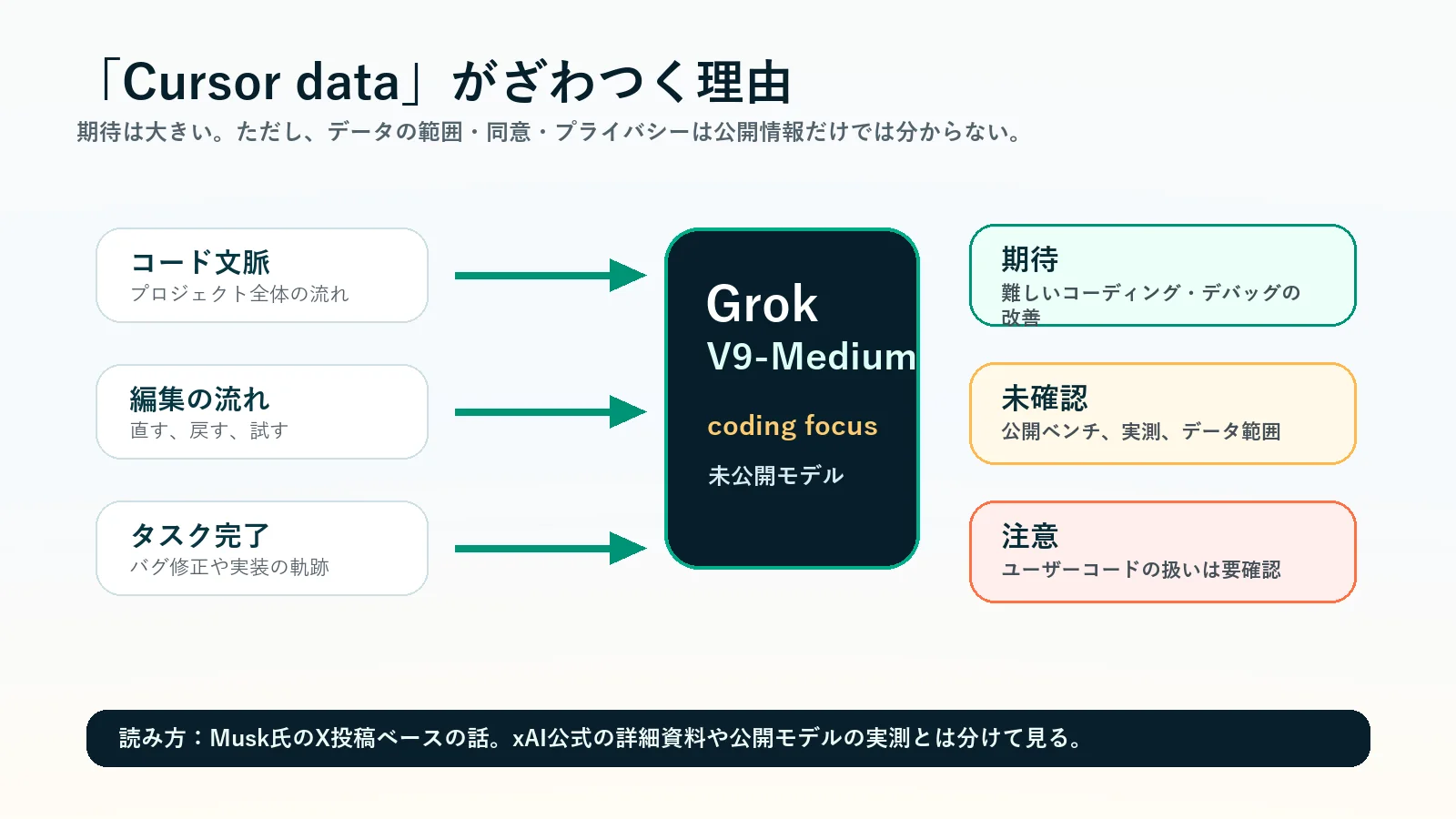
「Cursorデータ」がいちばんざわつく理由
今回の投稿でいちばん引っかかるのは、やはりCursorデータの部分です。
Cursorは、AIを使ったコーディング支援ツールとしてかなり存在感があります。公式サイトでも、コードを書くためのagentとして強く打ち出されています。だから、Grok側にCursor由来のデータが入るという話は、単に「コードをたくさん学習しました」よりも重く見えます。
コーディングAIで本当に難しいのは、完成コードだけを読むことではありません。人間がどう迷い、どこで修正し、どのファイルを見て、どうテストして、どこで諦めずに戻るのか。その流れをどれだけ学べるかが、実務での強さに直結します。
もしCursorデータが、そうした開発の流れを強める形で使われているなら、Grokは「普通に返答するAI」よりも、作業を進めるAIとして伸びる可能性があります。
ただし、ここは盛りすぎない方がいい
一方で、ここを「GrokがClaudeやCodexを完全に超える」と言い切るのは早いです。
コーディングAIの強さは、モデル単体だけで決まりません。リポジトリの読み方、差分の作り方、テストの回し方、エラーから戻る粘り、ツール使用、速度、料金、長時間作業での安定性。全部込みで体験が決まります。
特にCursorデータについては、公開情報だけでは分からない点があります。どの範囲のデータなのか、ユーザーコードの扱いはどうなっているのか、匿名化や許諾の設計はどうなっているのか。ここは、期待と同じくらい丁寧に見た方がいいです。
| 項目 | 今見えていること | まだ分からないこと |
|---|---|---|
| モデル規模 | 投稿では1.5Tと説明され、現行0.5Tから約3倍。 | サイズ増加がどれだけ実務性能に効くか。 |
| Cursorデータ | 補足訓練で多く追加されたとされる。 | データの範囲、扱い、同意、品質の詳細。 |
| 公開時期 | 2〜3週間後という見込みが投稿されている。 | 予定通り出るか、公開範囲や料金はどうなるか。 |
| コーディング性能 | 難しいタスクでの改善が期待されている。 | Claude、Codex、Geminiなどと比べた体感差。 |
公開までの流れはかなり短い
投稿ベースでは、今はfine-tuning中で、数日後にreinforcement learningが始まり、2〜3週間後に公開という流れです。2026年5月25日時点で見るなら、6月中旬あたりがひとつの目安になります。
もちろん、AIモデルの公開時期は動きます。評価で問題が出れば遅れるし、限定公開から始まる可能性もあります。だから、ここも「確定日」ではなく「目安」として見ておくのが安全です。
僕がいちばん見たいのは「修正の粘り」
僕の見方では、Grok V9-Mediumで本当に見たいのは、単発のコード生成ではありません。
難しいコーディングで大事なのは、最初の答えが当たることだけではなく、失敗したあとに戻れることです。エラーを読んで、原因を絞って、別のファイルも見て、修正して、テストして、また失敗したら別案を出す。この粘りがあるAIは、仕事でかなり使えます。
Cursorデータの話が本当に効くなら、この「開発者っぽい戻り方」が伸びるかもしれない。ここが僕は一番面白いと思っています。
逆に、チャットの回答が少し賢くなるだけなら、そこまで大きな変化ではありません。Grokが化けるかどうかは、IDEやターミナルの中でどれだけ仕事を進められるかで決まると思います。
日本の開発者にも関係ある話
日本では、AIコーディングの話になるとClaude、Cursor、Codex、GitHub Copilotあたりがよく名前に出ます。ここにGrokが本気で入ってくるなら、開発者の選択肢はかなり増えます。
特に、xAIは公式サイト上でもGrokのBuildやAPIを開発者向けに見せています。つまり、Grokは雑談AIだけではなく、コードや開発ワークフローにも入りたい。今回のV9-Mediumは、その方向をかなり強める話に見えます。
とはいえ、日本語の自然さ、ドキュメント読解、既存コードへの理解、長い作業での安定感は、実際に触らないと分かりません。ここで無理に勝敗を決めるより、公開後に同じタスクを複数モデルへ投げて比べる方がいいです。
古い0.5T系の公開話も追っておきたい
周辺では、現在の0.5T系モデルを年内にオープンソース化する話も出ています。これも本当なら面白いです。
ただ、どのモデルを、どのライセンスで、どこまで公開するのかによって意味が変わります。研究者やローカルLLM勢には刺さる話ですが、一般ユーザーや普通の開発者にとっては、まずV9-Mediumが実サービスでどれくらい使えるかの方が重要です。
まとめ:Grokが本気で「コードを書くAI」へ寄せてきた可能性
今回のGrok V9-Mediumの話は、まだ噂っぽさを残しています。公式ブログの詳細資料ではなく、Musk氏のX投稿が中心だからです。
でも、1.5T、Cursorデータ、2〜3週間後の公開見込みという組み合わせは、かなり強いニュースです。もし本当に難しいコーディングタスクで体感できる改善が出るなら、Grokの見え方は変わります。
僕は、Grokが「話題性のあるAI」から、開発者が毎日使うAIに近づけるかどうかを見たいです。
モデルサイズの大きさより、実際の修正力。派手な発表より、失敗したあとに粘れるか。そこに答えが出たとき、このニュースの本当の価値が分かると思います。