
2026年6月1日、AI界隈で一気に名前が広がったモデルがある。
MiniMax M3。
中国のMiniMaxが出してきた新しいfrontier multimodalモデルで、今日の話題性だけで言えばかなり強い。理由はシンプルで、コーディング、1Mコンテキスト、マルチモーダル の3つを、1つのモデルにまとめて押し込んできたからだ。
この記事の結論
- MiniMax M3は、長文・コード・画像/動画入力をまとめて狙う新モデル
- 1MトークンコンテキストとMiniMax Sparse Attentionが大きな売り
- SWE-Bench Pro 59.0%など、エージェント開発向けの数字が強い
- API価格が安く、OpenRouterなどでも注目されている
- オープンウェイト予定なので、公開後の検証が本番

MiniMax M3で何が起きたのか
MiniMax M3は、2026年6月1日に正式ローンチが報じられたMiniMaxの新モデルだ。
売り文句として強いのは、「3つのfrontier能力を1モデルにまとめた」 という点。具体的には、コーディング/エージェント性能、1Mトークン級の長文コンテキスト、そして画像・動画入力を含むネイティブマルチモーダルだ。
この組み合わせは、今のAIユーザーにかなり刺さる。単なるチャットではなく、コードベースを読み、画像や動画も見て、長い文脈を持ったまま作業するAIが求められているからだ。
なぜ「今日の目玉」なのか
MiniMax M3がバズりやすい理由は、かなり分かりやすい。
強そう、長く読める、マルチモーダル、しかも安い。
この4つが揃うと、AI界隈では一気に試される。特に、エージェント開発や大規模コードベースを触っている人にとって、1Mコンテキストはかなり魅力的だ。
| 注目点 | 何が嬉しい? | 刺さる人 |
|---|---|---|
| 1Mコンテキスト | 巨大な仕様書・長文ログ・大規模コードをまとめて扱いやすい | 開発者、分析者、研究者 |
| コーディング性能 | エージェント開発や修正タスクで使える可能性 | アプリ開発者、副業開発者 |
| マルチモーダル | 画像・動画入力を前提にした作業へ広がる | デザイナー、動画/画像制作者 |
| 価格 | 試行回数を増やしやすい | API利用者、AIツール運営者 |
ベンチマークと価格:かなり攻めている
話題になっている公式発表値では、SWE-Bench Proが 59.0%。Terminal Bench 2.1、SWE-fficiency、KernelBench Hard、MCP Atlasなどでもエージェント向けの強さをアピールしている。
もちろん、ベンチマークは実運用のすべてではない。けれど、今回のM3は「安いけど遊び用」ではなく、エージェント開発の実務候補 として見られているのが大きい。
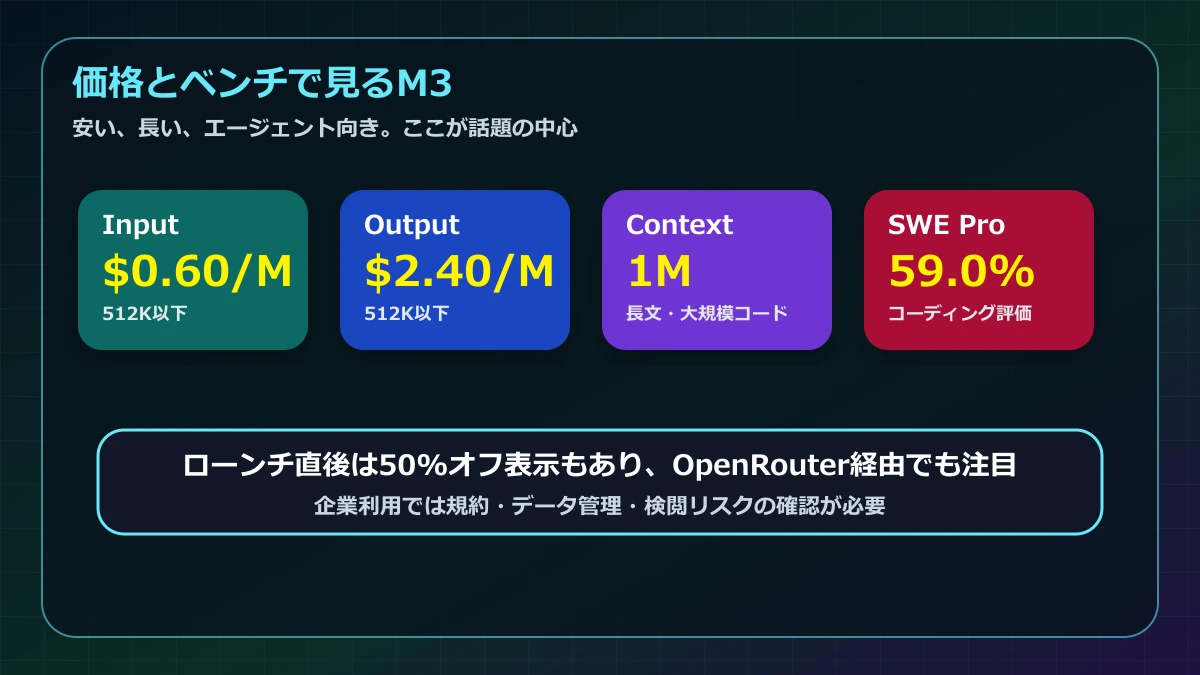
価格面では、512K以下のコンテキストで入力0.60ドル/100万トークン、出力2.40ドル/100万トークンという数字が出ている。OpenRouter側ではローンチ直後の50%オフ表示もあり、API利用者から見てもかなり試しやすい。
512Kから1Mの長文帯では価格が上がるが、それでも「長文を扱えるfrontier級モデル」と考えると、かなり攻めた価格に見える。
MiniMax Sparse Attentionとは何か
今回の技術的な目玉が、MiniMax Sparse Attention、略してMSA だ。
ざっくり言うと、長い入力のすべてを毎回フルで見るのではなく、まず軽い処理で「重要そうな場所」を選び、その場所を中心に本命の注意計算をする仕組みだ。
これによって、1Mトークン級の長文でも、従来より速く扱える可能性がある。

MiniMax M3では、1Mトークン時にM2比でPrefillが約9.7倍、Decodeが約15.6倍高速という数字が話題になっている。Prefillは長い入力を読み込む段階、Decodeは1トークンずつ出力する段階だ。
長文モデルで本当に困るのは、ただ「入る」だけではない。入っても遅い、重い、コストが高いと実務では使いづらい。M3はそこをかなり意識している。
マルチモーダルとComputer Useが熱い
MiniMax M3は、テキストだけのモデルではない。画像や動画入力を含むネイティブマルチモーダルが売りになっている。
これが強いのは、エージェントが現実の画面や資料を見ながら動く時代に入っているからだ。
たとえば、スクリーンショットを見てUI改善案を出す。動画を見て内容を要約する。操作画面を理解して次のアクションを提案する。こういう用途では、最初からマルチモーダルで作られているモデルの方が期待しやすい。
オープンウェイト予定がさらに火をつけている
MiniMax M3は、オープンウェイト予定も大きなポイントだ。
ただし、2026年6月1日時点では、記事執筆時点で完全な重みやライセンス条件の詳細がすべて出揃っているわけではない。公開予定という段階なので、商用利用、再配布、ローカル運用、微調整の条件は必ず確認が必要だ。
それでも、もし本当に強い性能と1Mコンテキスト、マルチモーダルを持つ重みが出てくるなら、ローカルAIや企業内AIの流れにもかなり効く。
ここは冷静に見たいところ
- オープンウェイトのライセンス条件は必ず確認
- 1Mコンテキストが実タスクでどこまで安定するかは検証待ち
- 中国企業モデルなので、企業利用ではデータ管理と規約確認が重要
- ベンチマークが強くても、自分のコード・資料・画像で試す必要がある
ブログ運営者・開発者はどう見るべきか
よへラボ的に見ると、MiniMax M3は「ただの新モデル」ではなく、AIツール作りやブログ運営にも関係する。
特に見るべきなのは、次の3つだ。
- 長文記事・大量資料の処理:1Mコンテキストが実用的なら、調査記事や比較記事の作り方が変わる
- AIエージェント開発:コードを読み、修正し、検証する流れに使える可能性がある
- 画像・動画込みの記事制作:スクショ、動画、UI、資料をまとめて理解する記事作成がしやすくなる
特に、AI検索時代の記事では、一次情報、構造化、比較、FAQ、表、図解が大事になる。M3のような長文・マルチモーダルモデルが増えると、AIに読み取られる記事の作り方もさらに変わる。
結論:MiniMax M3は「今日触りたくなる」モデル
MiniMax M3は、かなり派手な登場の仕方をした。
1Mコンテキスト、コーディング、マルチモーダル、MSA、低価格、オープンウェイト予定。AI好きが飛びつく要素がほぼ全部入っている。
もちろん、まだ検証待ちの部分はある。実際の開発現場でClaudeやGPT、Geminiと比べてどうか。長文でどれくらい崩れないか。オープンウェイト公開後のライセンスや実行コストはどうか。
それでも、今日のAIニュースとしてはかなり強い。
MiniMax M3は、中国発モデルが「安い代替」ではなく「frontier候補」として見られる流れをさらに進めた。
ここから10日前後で技術レポートや重み公開が進めば、さらに大きな波になる可能性がある。