
Claude Fable 5はAnthropicが2026年6月に一般公開した初のMythos-classモデルです。安全性を確保しつつ、従来のOpus 4.8を大幅に上回る性能を発揮。特に複雑なコーディングタスクや長時間agentic作業で革命的な進化を遂げています。
この記事では、公開されたベンチマーク数値、前モデルとの具体的な違い、安全機構の仕組み、他の競合モデルとの比較を徹底的に解説します。
この記事で分かること
- Fable 5の主要ベンチマークスコア(SWE-Bench Pro 80.3%など)とOpus 4.8との差
- 安全ガードレールの仕組みと影響範囲
- Agentic coding・長文タスクでの実用的な強み
- 料金・速度・おすすめの使いどころ
- 日本企業・エンジニアへの影響と今後の展望
Claude Fable 5とは? Mythos級モデルの位置づけ
AnthropicはこれまでOpusをフラッグシップとしてきましたが、Fable 5は「Mythos-class」と呼ばれる新しいティアの最初の一般公開モデルです。Mythosは元々内部や信頼できるパートナー限定で使われていた超高性能モデルで、OpenBSDの27年ぶりのバグ発見などの実績がありました。
Fable 5はその能力を安全に一般公開したもので、Mythos 5(緩和版)はGlasswingパートナーなどの信頼できる組織に限定公開されています。
ベンチマーク比較:Opus 4.8を圧倒する数字
Fable 5はほぼすべてのベンチマークでSOTAを達成。特に複雑・長時間タスクで差が大きくなります。
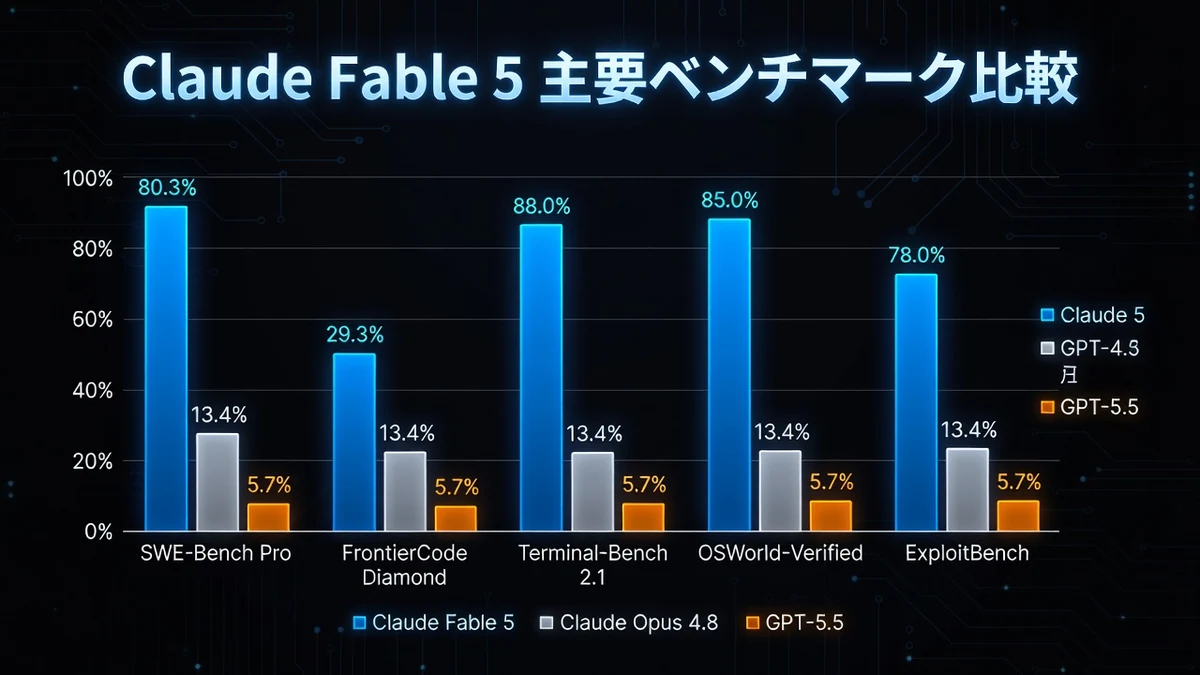
主要ベンチマークでFable 5がOpus 4.8やGPT-5.5を大きくリード
具体的なスコア
- SWE-Bench Pro: 80.3%(ソフトウェアエンジニアリング)
- FrontierCode Diamond: 29.3%(Opus 4.8: 13.4%、GPT-5.5: 5.7%)
- Terminal-Bench 2.1: 88.0%
- OSWorld-Verified: 85.0%
- ExploitBench(サイバーセキュリティ): 78.0%
多くのベンチマークでOpus 4.8に対して10〜20%以上の向上、 hardestタスクでは2〜3倍の差が出ています。
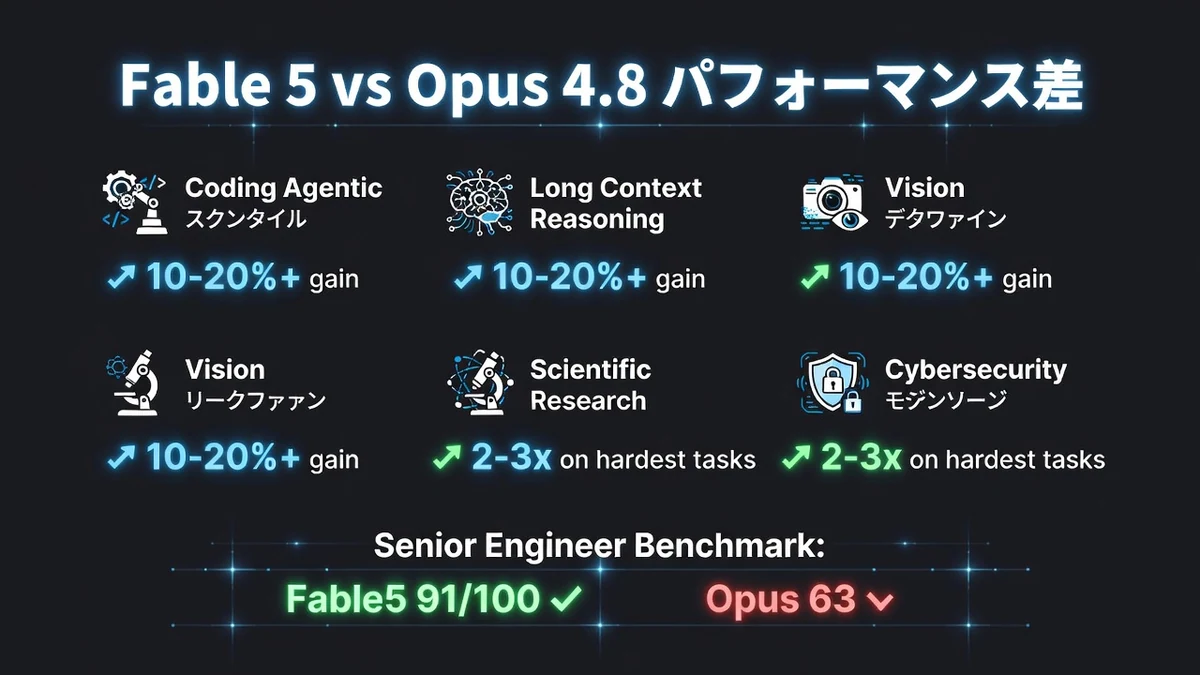
カテゴリ別性能差とSenior Engineerベンチマーク
安全ガードレールの仕組み
Fable 5の最大の特徴は、強力な能力を持ちながら安全性を確保するための「自動フォールバック」機構です。
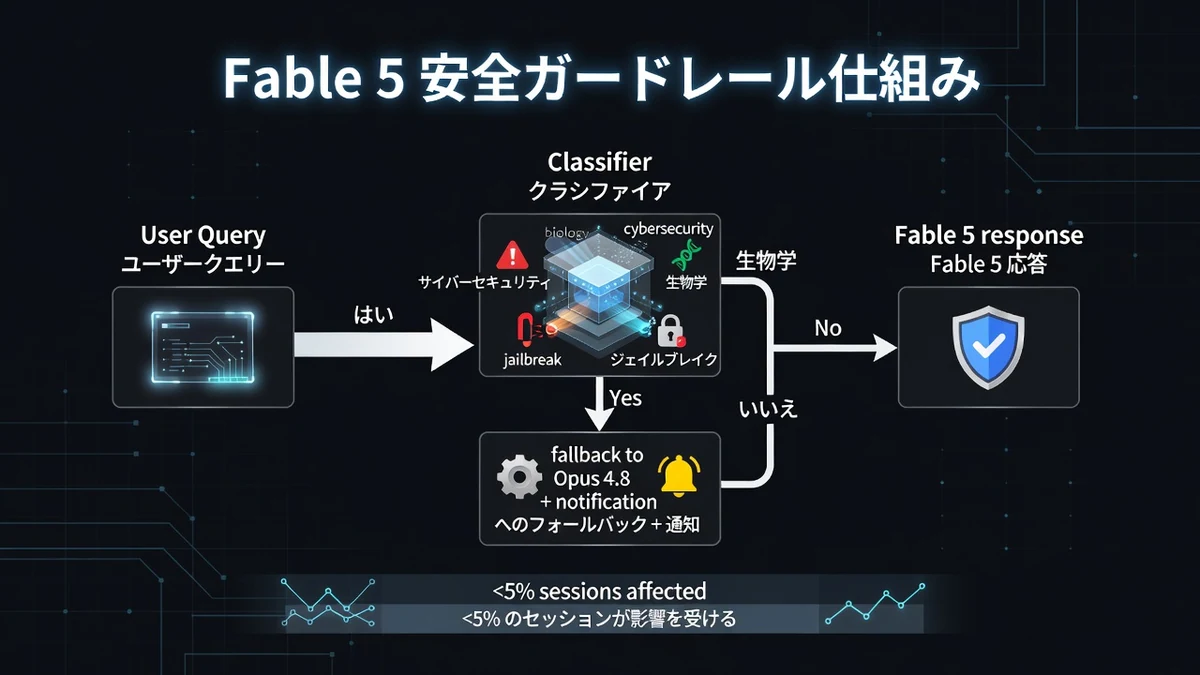
cybersecurity、biology/chemistry、jailbreak、model distillation関連のクエリを検知すると、自動でOpus 4.8に切り替わり、ユーザーに通知します。平均で5%未満のセッションに影響し、Anthropicはfalse positiveを減らすチューニングを続けています。
これにより、危険な領域での誤用リスクを大幅に低減しつつ、一般公開を実現しました。
他のモデルとの徹底比較
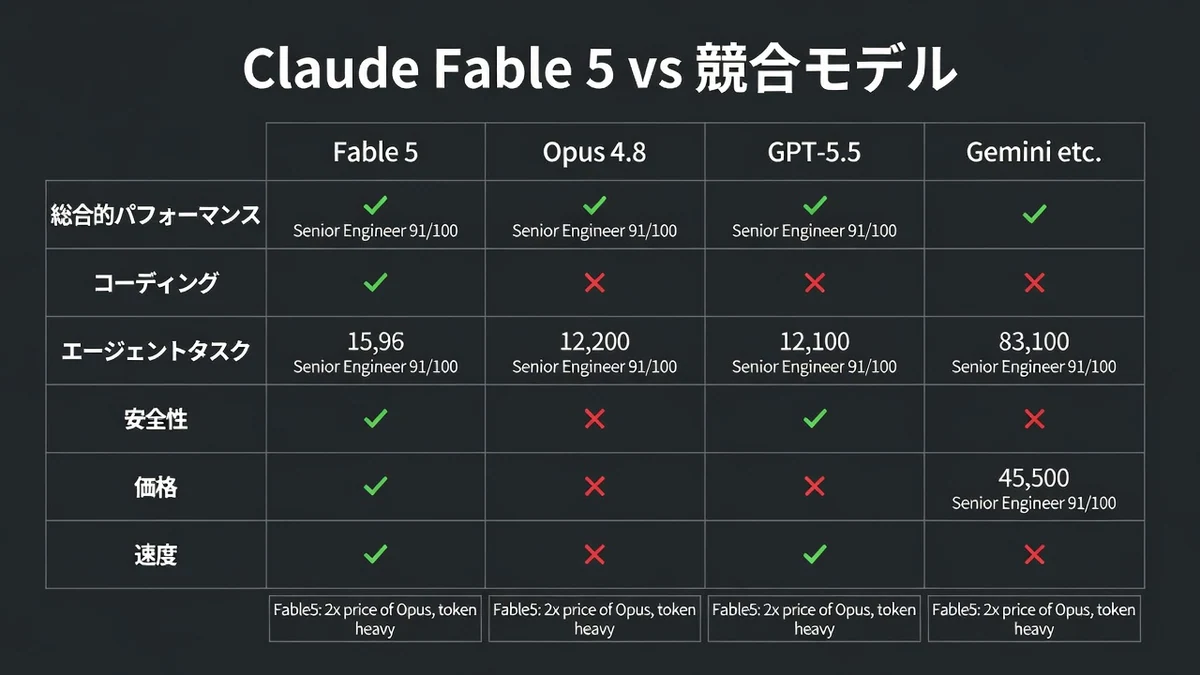
Fable 5は性能でリードするが、価格はOpusの約2倍、token消費量が多い
比較ポイント
- 性能: Fable 5 > Opus 4.8 > GPT-5.5(特にagentic・長文で顕著)
- 価格: Fable 5 ≈ $10 input / $50 output per M tokens(Opusの約2倍)
- 速度: やや遅め(複雑タスク向け)
- 安全性: Fable 5に専用classifier、Opusは標準
- トークン消費: 500k〜1M+ tokensが普通(token-hungry)
Agentic Codingでの強みと実例
Fable 5の最大の強みは「agentic coding」です。従来のモデルが「指示に従うツール」だったのに対し、Fable 5は「共同作業者」のように振る舞います。
- 大規模コードベースの一撃完成
- 自律的なデバッグ・自己検証
- 長時間(数日規模)のタスク継続
- サブエージェント委譲
- スクリーンショットからのアプリ再構築(vision)
Early testerからは「production backlogを一掃」「フルアプリをspecから構築」などの報告が相次いでいます。
料金・利用方法・おすすめの使いどころ
利用可能場所: claude.ai、Claude Code(claude --model claude-fable-5)、API、Amazon Bedrock
おすすめの使い方:
- 複雑なエンジニアリングプロジェクト
- 大規模リファクタリング・マイグレーション
- 科学研究・分析タスク
- 長時間agenticワークフロー
日常の軽いチャットや簡単な執筆には向かず、Opus 4.8や下位モデルで十分な場合はそちらを使うのが賢明です。
日本への影響とJapan AI Indexとのつながり
AnthropicはPKSHA Technologyと東京大学松尾・岩澤研と共同で「Japan AI Index」を構築中です。Fable 5のリリースは、日本企業のAI戦略立案に大きな材料を提供します。特に高齢化・労働力不足を抱える日本にとって、agentic codingの進化は生産性向上に直結する可能性が高いです。
X上の反応とコミュニティの声
リリース直後から「game changer」「senior engineerレベル」「tokenはかかるが価値あり」などの声が殺到。memeやSolanaトークン$ FABLEまで登場するほど話題になりました。
注意点
- 価格が高め(Opusの2倍程度)でtoken消費量が多い
- 速度が遅めなので軽いタスクには不向き
- 安全フォールバックが働くクエリではOpus 4.8相当の性能になる
- 利用上限やレートリミットに注意
まとめ
Claude Fable 5は、Anthropicが初めて一般公開したMythos級モデルとして、性能・安全性のバランスを両立させた画期的なリリースです。特にソフトウェアエンジニアリングやagenticタスクでこれまでの常識を覆す性能を発揮します。
ただし、価格とtoken消費を考慮すると「すべての作業をFable 5で」というより、「本当に難しいタスクだけFable 5を使う」戦略が最適です。
FAQ
Q1. Fable 5は誰でもすぐに使えますか?
A. はい、claude.aiやAPIですぐに利用可能です。Claude Codeでは /model claude-fable-5 で切り替えられます。
Q2. Mythos 5との違いは何ですか?
A. Mythos 5は安全ガードレールを緩和したバージョンで、現在はGlasswingパートナーなど限定公開です。将来的に信頼できる研究者向けに拡大予定です。
Q3. 日常使いには向きますか?
A. 向いていません。価格と速度から、複雑なプロジェクトやagenticワークフローに特化して使うのがおすすめです。軽い作業はOpus 4.8や下位モデルで十分です。